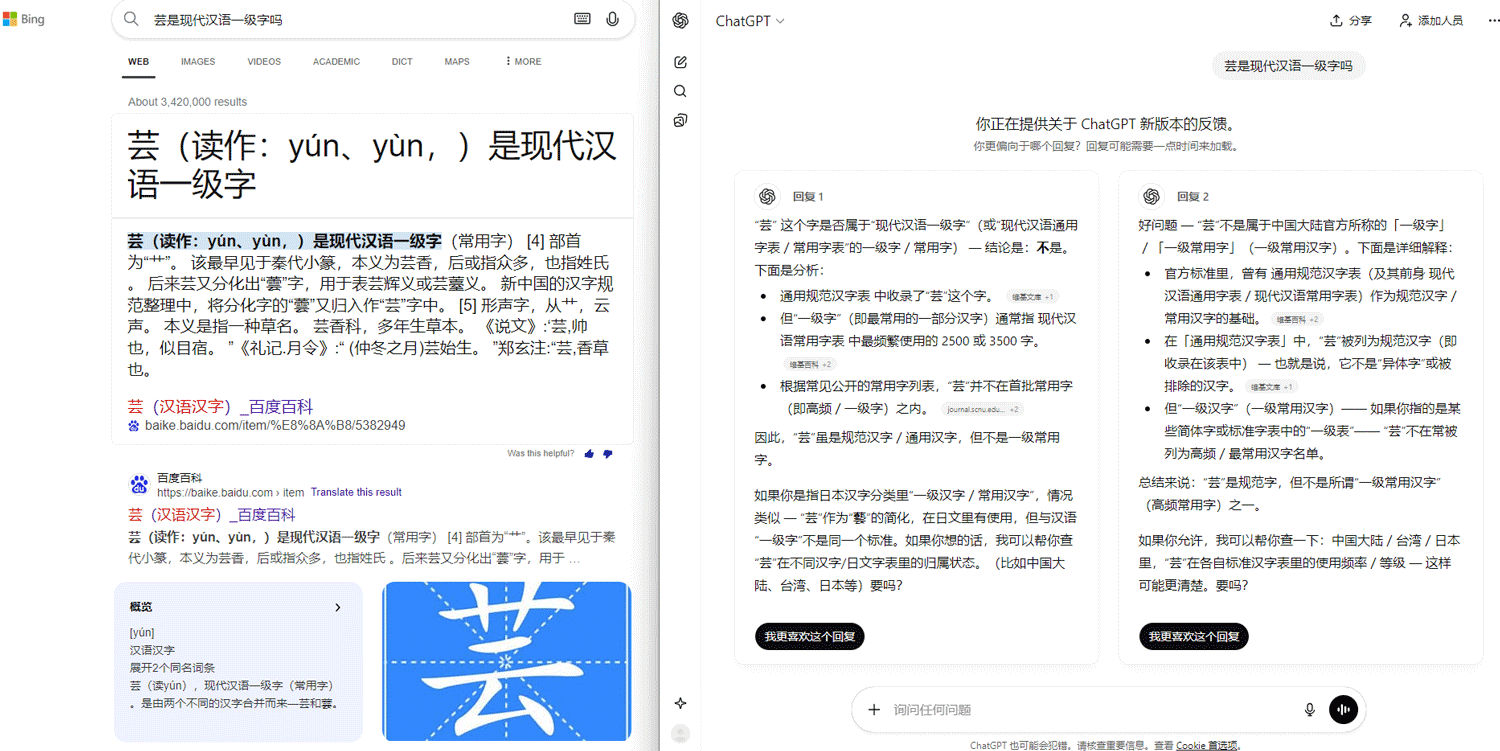
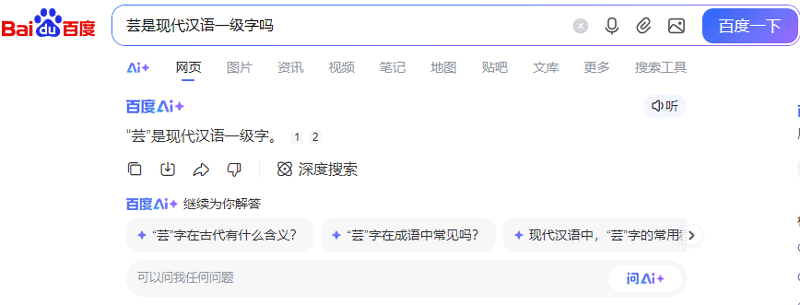
比如下面的问题,我一直以为某些常用字是在《通用规范汉字表》的一级字表里面的,其实不在,还好我对bing里的baidu搜索结果和国内部分AI一直都不是很信任
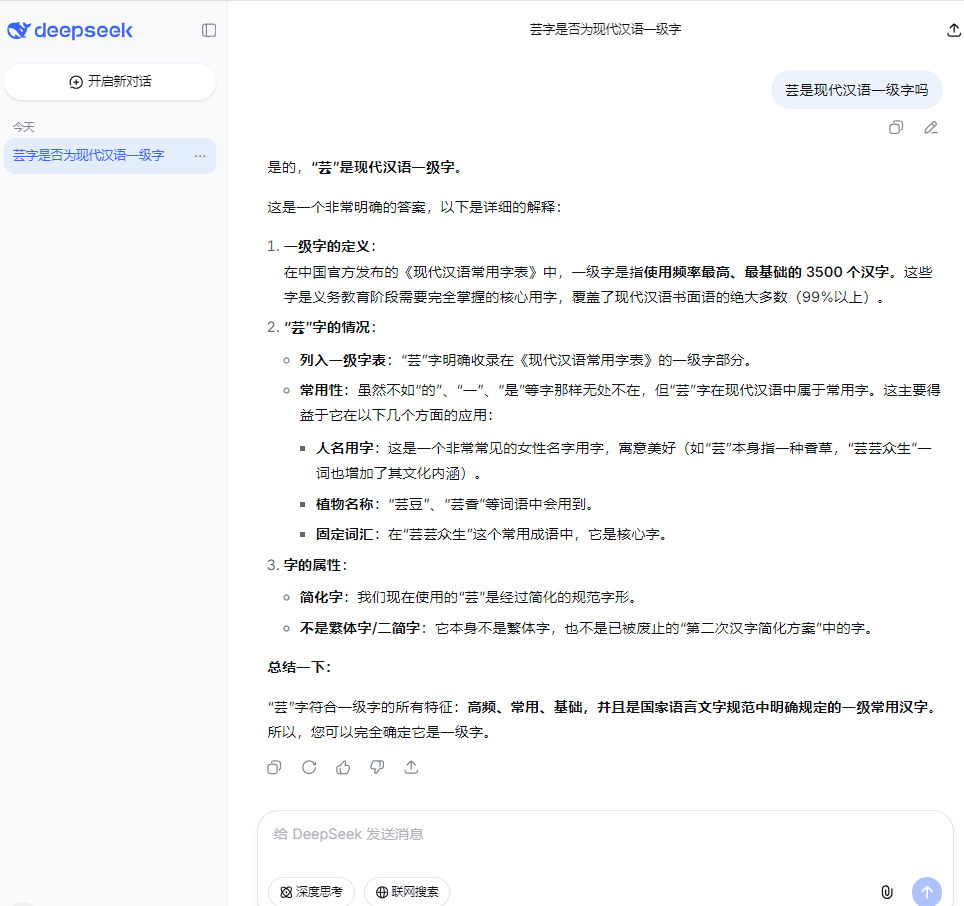
deepseek 众所周知的幻觉严重,国内目前各方面最好的是千问 Qwen,是目前开源模型里面公认比较强的
1 个赞
Qwen我也听过N次了,但还没有用过,大佬推荐那就试一下,发现果然没错,Qwen的答案是对的
你这个其实只说明了维基百科和百度百科的数据质量问题,而且对于这个问题你比较倾向于维基百科的数据,至于bing觉得百度百科权重高而chatgpt背后的搜索引擎优选维基百科,那是他们其它方面的问题了,说不定你用英文问一遍同样的问题结果又不一样。
用搜索引擎和ai大模型回答你的问题,你本身就需要有一定的鉴别能力,不能只靠它们投送,毕竟维基百科的数据也是良莠不齐。
如果你知道一个你特别信任的数据源,你最好直接指定ai去那获取数据,比如医疗相关的,你觉得默沙东比较靠谱,就直接让ai去那检索数据。
如果你都不知道,找些deep research工具,去帮你简化一些查证流程。
1 个赞
没用的。 我叫ai帮我找点东西,都是直接编的。
这个问题应该确实是数据质量原因导致的,但我觉得ai应该有能力识别低质量数据,有验证数据真假的能力(通过逻辑推理判断等)。 还是说现在的AI并不具有这种能力, 只能依赖数据本身, 那这样AI就实际就还只是一个搜索引擎的升级版,实用价值较低。
现在的 reasoning model 也会模拟人的方式去做"推理",一定程度上能够改善胡说八道的问题。
其实并没有取代。AI的信息不是最新,AI还是要通过web search来帮你搜索。它还是只是加快了检索的速度,帮你总结。但是无论Chatgpt还是claude什么的,都离不开搜索引擎。SEO还是SEO。但是有一个非常不好的地方,AI现在搜索,即使是所谓的deep research,也是很简陋的搜索,有时候一个问题,就一直重复在引用某一篇博客的内容。例如最近在研究怎样嵌入godot到ios里面,AI就一直反复的引用同一篇技术博客的内容,并有的无的添油加醋,一篇博客非要弄成几十页的markdown看都看晕了(还不如自己传统的阅读技巧直接去看原文 )。不过在大部分情况下,deep research还是很有用的,特别是对自己不熟悉的话题上做一些初步的研究。
2 个赞
现在很少人生成高质量的内容了,AI只会让垃圾内容越来越多,搜索引擎哪怕是错误内容也有一定的可取价值的。
最近听了Can We Save The Web From AI? — With Cloudflare CEO Matthew Prince的播客,截取一些相关内容:
AI与搜索的根本区别在于:
* **搜索引擎**:提供10个蓝色链接,引导用户点击进入原始网站寻找答案。
* **AI模型**:直接整合信息,向用户提供一个最终的、合成的答案。
数据:
* **与Google的交易演变**:十年前,Google的模式是“每抓取2次页面,带来1次点击”。这是一个相对健康的交换。十年间,互联网用户从40亿增长到60亿,按理说获取流量应该更容易。但现实恰恰相反。
* **6个月前**:比例恶化到“每抓取6次,带来1次点击”。这是因为Google开始在搜索结果页面直接提供答案框,用户无需再点击链接。当时,约75%的查询已能在Google页面内直接得到解答。
* **现在**:随着Google推出“AI Overviews”,比例进一步恶化到“每抓取18次,带来1次点击”。内容创作者的回报率大幅降低。
* **AI爬虫的“零和游戏”**:与Google相比,新兴的AI爬虫表现出一种近乎“掠夺性”的模式。
* **OpenAI**:获取一次点击的代价是“抓取1500次页面”。
* **Anthropic**:情况更糟,这个数字高达“抓取60,000次页面,才换来1次点击”。
这种转变意味着用户不再需要访问原始信源。当用户不再访问网站时,上述所有的变现渠道——订阅、广告、甚至影响力——都会失效。
AI爬虫对内容创作者造成的伤害是双重的:
1. **直接的经济成本**:每次爬虫访问网站,都会消耗服务器资源(CPU、带宽)。网站所有者需要为此支付实际的费用。Wikipedia就是一个典型例子,其因AI爬虫的频繁访问而面临服务器成本飙升的问题。内容创作者实际上是**自掏腰包**为这些AI公司的模型训练和运营“买单”。
2. **知识产权与价值窃取**:AI公司通过抓取内容来训练其基础模型或进行实时信息检索(如通过RAG技术)。这些内容是AI公司产品的核心“燃料”。**如果没有这些内容,AI模型将变得“愚蠢”**。因此,AI公司从内容中获得了巨大价值,但内容创作者却未得到任何补偿。
旧的“Google交易”是“我们复制你的内容,我们给你流量”。现在,这个交易变成了“**我们复制你的内容,我们什么都不给你**”。
如果趋势不扭转,可以预见以后ai给的答案也会越来越傻
2 个赞
这方面我感觉chatGPT是最好的, 有时问他一个问题, 会把用到的资料网页链接在后面列出十多个来, 虽然用户一般也不会点, 但也还是应该给出.
有时候让他写个脚本, 没讲明离线就会写成在线的形式, 即把需要获取的数据链接直接写进代码里, 代码运行时去链接中抓取数据, 结果那个链接还是打不开的(在国内)
但整个趋势依然是原创的内容越来越少,垃圾内容越来越多。
引用一段 @ActionAgain 的话
在这个AI时代的新纪元,洞见与观点越发弥足珍贵,重复的知识毫无半点价值。
AI不仅不会过滤错误信息,而且还会编造信息。
学术文献是个重灾区。所有AI都缺少专业学术文献的训练,一个个还都煞有其事地编造一些文献出来。配合一些相关专业领域搜索的MCP可以显著提高相关体验。
1 个赞
有没有一种可能, 在AI还没有流行起来以前, 学术文献这一邻域就已经是错误虚假信息泛滥成灾了的, 只是因为普通人缺少专业能力, 识别不出来而已。
比如本贴开头的问题, 如果没有AI, 我也就被骗过去了, 正是因为有AI, 普通人也可以识别出学术文献很多都是编造出来的。
1 个赞
不是这个问题。学术研究成果造假和编造根本不存在的学术成果是两个事情。
1 个赞
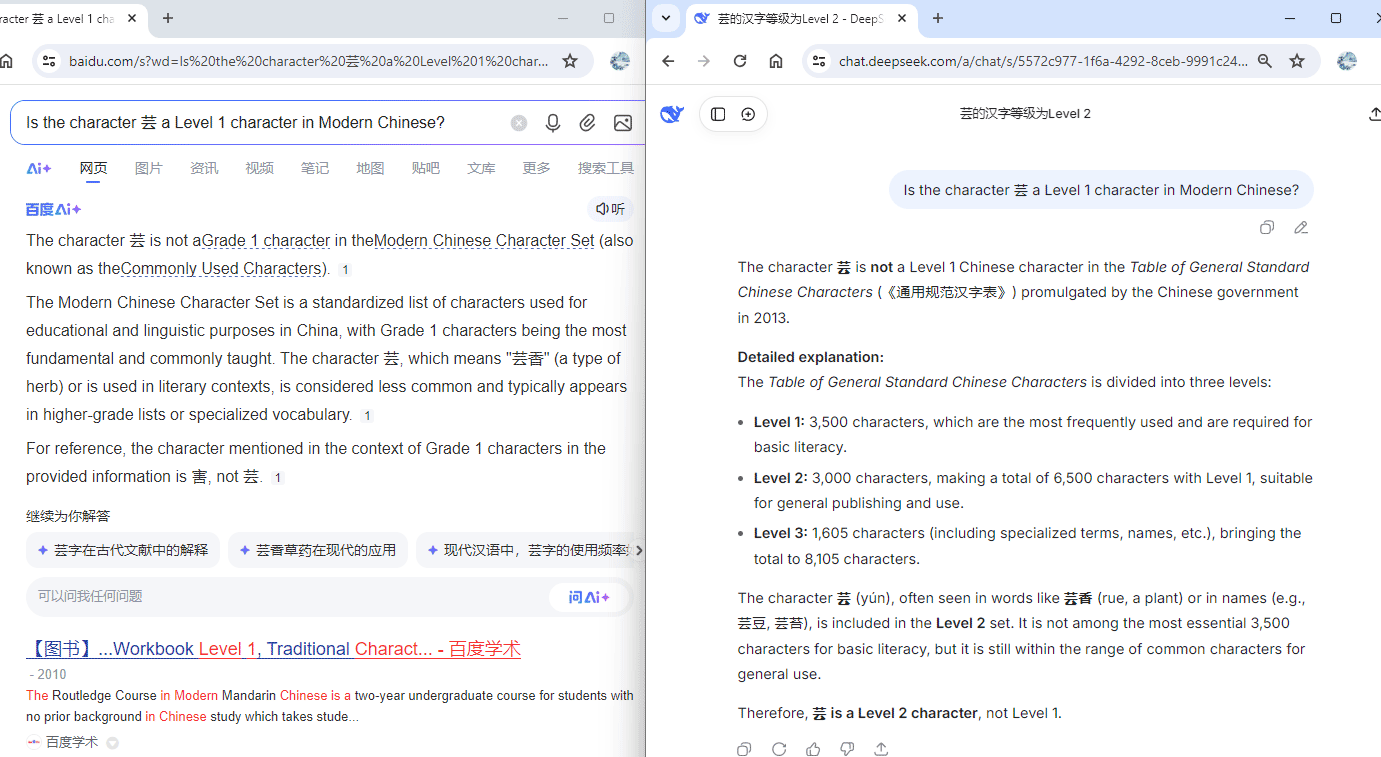
没有 ![]() 我不是这个意思。我觉得这个case可能就是训练的或者搜寻到的中文数据被污染了,仅此而已;英文预料或者英文检索数据自有它们被污染的part,只是你不是英文母语者可能不容易落在那个分布而已。
我不是这个意思。我觉得这个case可能就是训练的或者搜寻到的中文数据被污染了,仅此而已;英文预料或者英文检索数据自有它们被污染的part,只是你不是英文母语者可能不容易落在那个分布而已。
看了半天才看懂,你说的搜索引擎是指搜索引擎的 AI 回答,那不也是 AI 么 ![]()
在我的认识里,你给什么数据、语料他最终就只能输出什么数据、语料,不能脱离这个范围的这种(比如分析数据是否合理)依然还只能算是搜索引擎,这种东西在chatGPT还没有流行以前就已经存在了,当时也被认为是不实用的,很少有人会把它当作AI。
不知道怎么就现在万物都AI了
LLM 和它的区别也只是最终输出一个 token 级的概率分布而已。
因为它就是用 LLM 生成的。 我重看了一下才发现你的第一章图里 Bing 并不是 AI 回答,下面的百度是。