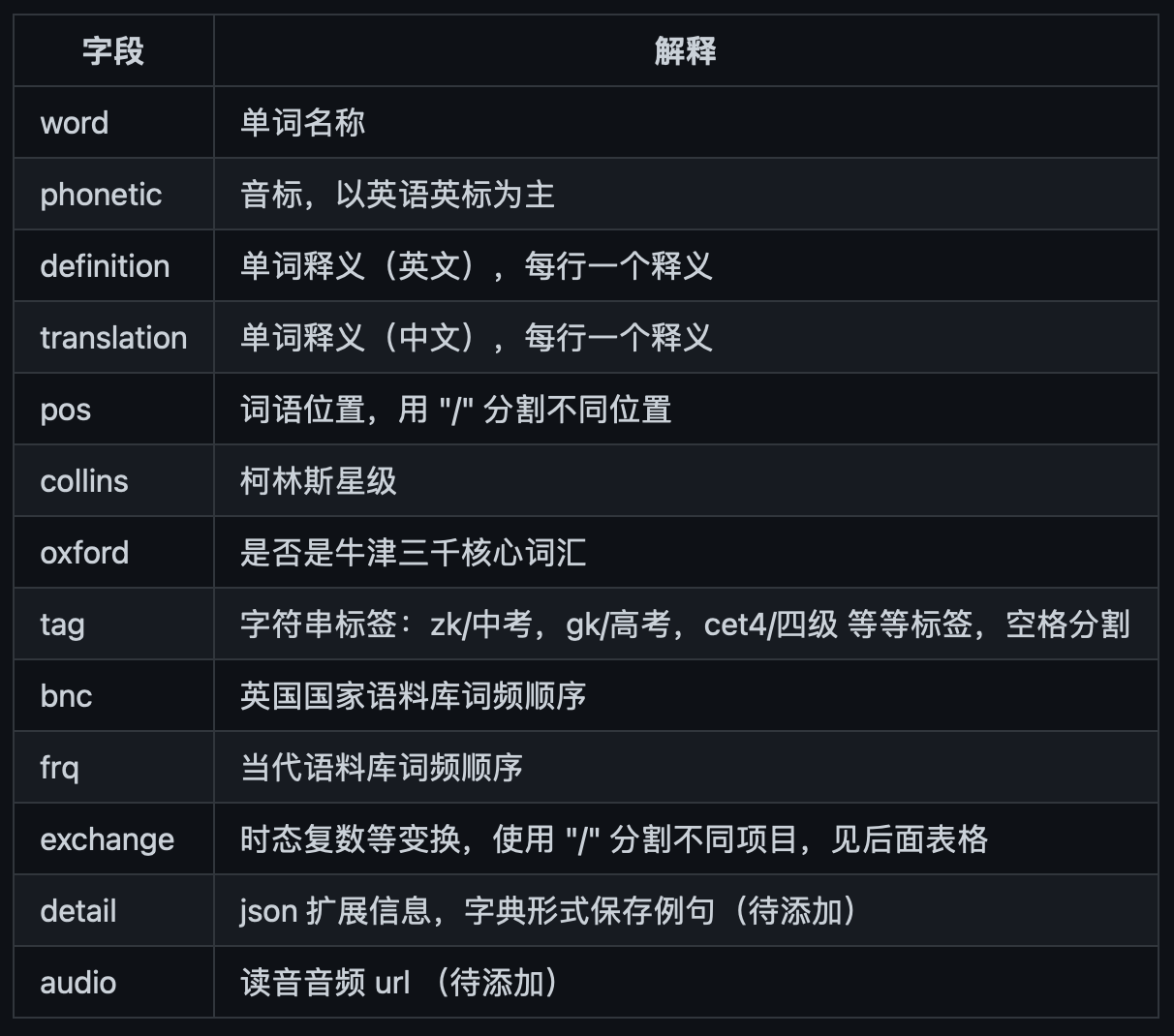
@zbelial 这个功能看起来可行。

扫描当前buffer,提取所有的单词。如果单词不在knownword.txt,则翻译一下。通过添加overlay 来改变当前buffer 的展示:英文(中文翻译)
目前我写了个demo,当自己什么单词都不认识。会翻译所有。然后一个个添加到 knownword.txt
可以在网上找一个四六级的词库,当作自己的 knownword.txt
@zbelial 这个功能看起来可行。
扫描当前buffer,提取所有的单词。如果单词不在knownword.txt,则翻译一下。通过添加overlay 来改变当前buffer 的展示:英文(中文翻译)
目前我写了个demo,当自己什么单词都不认识。会翻译所有。然后一个个添加到 knownword.txt
可以在网上找一个四六级的词库,当作自己的 knownword.txt
大佬, 你这个效果很不错啊
Good! 怎么能试用上这个功能谢谢
英语不好的人的无尽挣扎。
现在缺一个离线的,只有一个词义的好用的中英词典。
目前我使用了你提到的类似用:puppeteer + deepl 的形式,捞当前 buffer 的生词,翻译一下。然后存起来,下次就直接查本地文件。如果不断的阅读新的内容,就可以不断扩展自己的词库了。
目前还只是demo,还需要开发。下周看看如果能自己日常使用了,就发出来。
用户体验的话,建议手动翻译过的就加生词本,有可能下次还不记得,只生词本的翻译,直到用户彻底会了,从生词本取消某个单词。
这个比默认翻译所有单词再去掉会的,少很多操作。
好的,建议采取行间显示释义的办法,这样括号会少些也不会使句子一断一断的
这个词典还挺全的,就是释意的内容太多。我这里只需要一个释意,并且希望它尽可能是最常用的。需要它简洁,不需要详情信息。我当前选择使用在线翻译而不是在线词典,就是因为翻译获取的结果是最简洁的。
可以看看我是否能写个sql 清洗一下词典,使用在线翻译,如果当前buffer 生词太多,会比较慢
为了解决一个问题是,每次阅读时,指针跳转到不认识的单词,然后运行查询词典,容易打断阅读思路。因此希望自动展示你可能不认识的单词解释。
可以使用两种模式:生词本模式和熟词本模式
熟词本模式对于英文不好的人有两个问题:
哈哈。是的。可以先按照一个模式,完成一个可用的版本。后续再慢慢调整。
PS. 使用 python 实现中。发现自己对 python 的协程理解有问题。配合 websocket + playwright 总有一些奇怪的问题。还在学习中。
生词本和熟词本可以来回切换就好了,不过这样的话就需要分别设置添加到生词本和熟词本的功能。
Python 尽量用多线程, 除非遇到服务器后台那种, IO密集到影响性能的场景才用协程。
协程了解的不多, 总会给人感觉协程更高级, 协程一旦遇到CPU密集型的代码, 就会导致事件循环根本没有机会切换到其他协程。
Python的线程依然是在大部分场景更适用的方案。
这个估计是可行的。主动查询单词时,把这个单词添加到生词本,把它从熟词本里剔除。
其实对于英语不好的人(比如我), 更符合直觉的是:
这些功能都还好, 主要的是大部分获取英文材料的场景都是浏览器, 其实楼主做好文本的功能, EAF其实有一个 switch_to_reader_mode 的模式(如下图二而所示), 可以把网页中真正重要的中间文字抽出来(过滤掉网页左右两边的导航等控件), 我再把ReaderMode的文字转换成 Emacs Text Buffer, 就可以快速学习了。
我个人是觉得,我的这个场景使用多线程应该就可以了。 一个线程进行 websocket 通信, 一个线程使用 playwright 打开浏览器查词语。
只是 websockets 和 playwright 库默认 example 就是使用 asyncio, 所以就按照示例来了。顺便学习学习。
这个抽取文本的功能很赞耶。
我现在阅读材料,基本都是save-everything 的形式。只要是大体上有价值的问题。我都会使用 firefox 的插件,抽取为 org mode,保存下载。然后某个时间,自己随机浏览一下以前看过的文档。用于回顾,整理。
其实我发现 EAF Browser 很早就有这两个功能:
上面这两个命令都是基于 Mozilla 的 Readability.js 来实现的, 效果非常好。
只是原来做出来后, 没有想到合适的应用场景利用这个功能就没管了, 如果能够对接楼主的英文学习插件, 基本上以后就是EAF Browser查资料, 遇到不懂的网页立马进入英文学习模式去看材料, 就可以大大提高学习的速度了。
楼主的文本翻译插件出来以后, 大家可以双剑合璧一下:
这样基本上学习任何技术, 都可以快速弄懂英文材料在说啥。