请接受我的核武器打击:
其实不太同意一些观点:
elisp太古老了,emacs太独特了,这种上古技术,就像一把绝世好剑,注定能用好它的人会很少。这意味着你写出来的东西很多人都看不懂,当然也就无法进行技术交流互动了,自己造轮子造到心累。
博主似乎不知道 emacs-china 的存在。
请接受我的核武器打击:
其实不太同意一些观点:
elisp太古老了,emacs太独特了,这种上古技术,就像一把绝世好剑,注定能用好它的人会很少。这意味着你写出来的东西很多人都看不懂,当然也就无法进行技术交流互动了,自己造轮子造到心累。
博主似乎不知道 emacs-china 的存在。
博客很不错呀 
我的建议是,仍然使用 clock 功能,然后利用 org-clock-report 来汇总,具体来说可以这样:
** 阅读《GEB》
:LOGBOOK:
CLOCK: [2019-12-28 六 19:50]--[2019-12-28 六 20:16] => 0:26
CLOCK: [2019-12-27 五 19:50]--[2019-12-27 五 20:00] => 0:10
CLOCK: [2019-12-26 四 19:40]--[2019-12-26 四 20:14] => 0:34
CLOCK: [2019-12-25 三 19:50]--[2019-12-25 三 20:13] => 0:23
CLOCK: [2019-12-24 二 19:50]--[2019-12-24 二 20:18] => 0:28
:END:
#+BEGIN: clocktable :scope subtree :block untilnow
#+END
#+BEGIN 所在一行,执行 C-c C-c(或 M-x org-control-c-control-c),将会得到如下结果 #+BEGIN: clocktable :scope subtree :block untilnow
#+CAPTION: Clock summary at [2020-02-11 二 11:53], for now.
| Headline | Time | |
|-----------------+------+------|
| *Total time* | *2:01* | |
|-----------------+------+------|
| \_ 阅读《GEB》 | | 2:01 |
#+END
见文档:The clock table (The Org Manual)
至于你说的只能有一个正在运行的 Clock,那读书和平时的任务就冲突了,一个办法是用 org-capture 来新建任务,通过 :clock-resume 来在完成一个任务后恢复原来的计时任务,详见文档:Template elements (The Org Manual) (搜索 clock-resume)
李杀也不用 org-mode,手撸 html,都二十年了,我也想尝试一下。
谢谢,我感觉这样的话,和我期望的目标已经很接近了。
就是这个 Clock 还是要占用 Org Mode 任务的 Clock,不知道有没有办法能有多个 Clock 呢?
而且,如果同时在读多本书(时间精确度不需要太细),只有唯一的 Clock 也不能实现。
手动记一下
这样的话,就丢失了 Org Mode 的统计能力
我其实没太懂
org-clock-in 都会在一个条目下生成一个时间记录,一个条目下是可以有多个时间记录的,不同的条目可以有自己的 clock 记录,不知道你说的多个 clock 是指什么下面这样的记录不满足你的要求吗?
** 阅读《GEB》
:LOGBOOK:
CLOCK: [2019-12-28 六 19:50]--[2019-12-28 六 20:16] => 0:26
CLOCK: [2019-12-27 五 19:50]--[2019-12-27 五 20:00] => 0:10
CLOCK: [2019-12-26 四 19:40]--[2019-12-26 四 20:14] => 0:34
CLOCK: [2019-12-25 三 19:50]--[2019-12-25 三 20:13] => 0:23
CLOCK: [2019-12-24 二 19:50]--[2019-12-24 二 20:18] => 0:28
:END:
#+BEGIN: clocktable :scope subtree :block untilnow
#+CAPTION: Clock summary at [2020-02-11 二 11:53], for now.
| Headline | Time | |
|-----------------+------+------|
| *Total time* | *2:01* | |
|-----------------+------+------|
| \_ 阅读《GEB》 | | 2:01 |
#+END
** 阅读《世界观》
:LOGBOOK:
CLOCK: [2019-12-28 六 19:50]--[2019-12-28 六 20:16] => 0:26
CLOCK: [2019-12-27 五 19:50]--[2019-12-27 五 20:00] => 0:10
CLOCK: [2019-12-26 四 19:40]--[2019-12-26 四 20:14] => 0:34
CLOCK: [2019-12-25 三 19:50]--[2019-12-25 三 20:13] => 0:23
CLOCK: [2019-12-24 二 19:50]--[2019-12-24 二 20:18] => 0:28
:END:
#+BEGIN: clocktable :scope subtree :block untilnow
#+CAPTION: Clock summary at [2020-02-11 二 11:53], for now.
| Headline | Time | |
|-----------------+------+------|
| *Total time* | *2:01* | |
|-----------------+------+------|
| \_ 阅读《世界观》 | | 2:01 |
#+END这个 clocktable 能不能放在一级 headline 下,然后统计所有二级 headline 的时间?像这样放在每个二级 headline下,每增加一个 「阅读 **」书的 headline,就要增加一行这个 clocktable 语句,感觉略繁琐。
可以的,我只是为了方便理解写了一个相对简单的示例而已。这个 report 是可以做很多设置的,看下我贴的文档链接吧。
一个示例如下:
* 读书记录
#+BEGIN: clocktable :scope subtree :block untilnow
#+CAPTION: Clock summary at [2020-02-11 二 17:01], for now.
| Headline | Time | |
|--------------------+------+------|
| *Total time* | *4:02* | |
|--------------------+------+------|
| 读书记录 | 4:02 | |
| \_ 阅读《GEB》 | | 2:01 |
| \_ 阅读《世界观》 | | 2:01 |
#+END
** 阅读《GEB》
:LOGBOOK:
CLOCK: [2019-12-28 六 19:50]--[2019-12-28 六 20:16] => 0:26
CLOCK: [2019-12-27 五 19:50]--[2019-12-27 五 20:00] => 0:10
CLOCK: [2019-12-26 四 19:40]--[2019-12-26 四 20:14] => 0:34
CLOCK: [2019-12-25 三 19:50]--[2019-12-25 三 20:13] => 0:23
CLOCK: [2019-12-24 二 19:50]--[2019-12-24 二 20:18] => 0:28
:END:
** 阅读《世界观》
:LOGBOOK:
CLOCK: [2019-12-28 六 19:50]--[2019-12-28 六 20:16] => 0:26
CLOCK: [2019-12-27 五 19:50]--[2019-12-27 五 20:00] => 0:10
CLOCK: [2019-12-26 四 19:40]--[2019-12-26 四 20:14] => 0:34
CLOCK: [2019-12-25 三 19:50]--[2019-12-25 三 20:13] => 0:23
CLOCK: [2019-12-24 二 19:50]--[2019-12-24 二 20:18] => 0:28
:END:
新的问题: 怎么在此基础上,汇总每年的阅读总时间?类似如下:
| Headline | Time | |
|------------------------+-----------+-------|
| *Total time* | *260:32:10* | |
|------------------------+-----------+-------|
| 2019 | 128:17:02 | |
| \_ 阅读《道德经》 | | 2:11 |
| \_ 阅读《庄子》 | | 12:01 |
| ... | | ... |
| 2020 | 132:15:08 | |
| \_ 阅读《曾国藩》 | | 3:02 |
| \_ 阅读《大唐悬疑录》 | | 10:01 |
| ... | | ... |
解决了,加个 :maxlevel N.
还可以 :block thisyear,或者指定年份的话可以 :block 2017
再说一遍,看文档啊! ლ(╹◡╹ლ)
不好意思,我没有描述清楚。
org-clock-in 已经能很好满足我的需求了,我也想用 org-clock-in
同时读多本书是指什么?
就像我上面说的,记录不需要精确到秒,举个例子就是像你说的 《世界观》 和 《GEB》 交错着看。有一条 CLOCK: CLOCK: [2019-12-12 Thu 10:21]--[2020-02-12 Wed 10:21] => 1488:00 对我来说就足够了,需要每次看的时候都 clock-in
主要的问题是:我通过 org-clock-in 在 《世界观》 增加一个记录,当我在《世界观》 下使用 org-clock-in 时,会自动 org-clock-out 了《世界观》 的记录。
clock-in 一个记录时另外一个 clock-out 这个我觉得没有什么问题,设计就是这个样子……
如果你是要记录一本书从开始看到结束这中间的时间,而不是精确的在读的时间,那我觉得你不需要用 clock 功能,clock 功能应该也不是为此设计的。
你可以直接用 TODO -> DOING -> DONE 的状态变化:
上述完整过程我不知道有没有现成的功能、工具支持,或许需要自己写一点代码。
另外,豆瓣读书的标记功能是不是就是你想要的?对任意一本书标记成在读,读完后标记一下读完,然后帮你计算一个读了多少天?
基本就是你说的思路了,找个时间试着写一下,谢谢
真有好东西O(∩_∩)O
想把 mode-line 信息改动一下:
不显示总时间, 只显示当前 clock 的计时.
** 阅读《GEB》
:LOGBOOK:
CLOCK: [2020-03-29 五 01:49]
CLOCK: [2019-12-28 六 19:50]--[2019-12-28 六 20:16] => 0:26
CLOCK: [2019-12-27 五 19:50]--[2019-12-27 五 20:00] => 0:10
CLOCK: [2019-12-26 四 19:40]--[2019-12-26 四 20:14] => 0:34
举个例子: 进入任务:阅读《GEB》后
mode-line 显示的是从 [2020-03-29 五 01:49] 开始的时间.
Solved:
(setq org-clock-mode-line-total 'current)
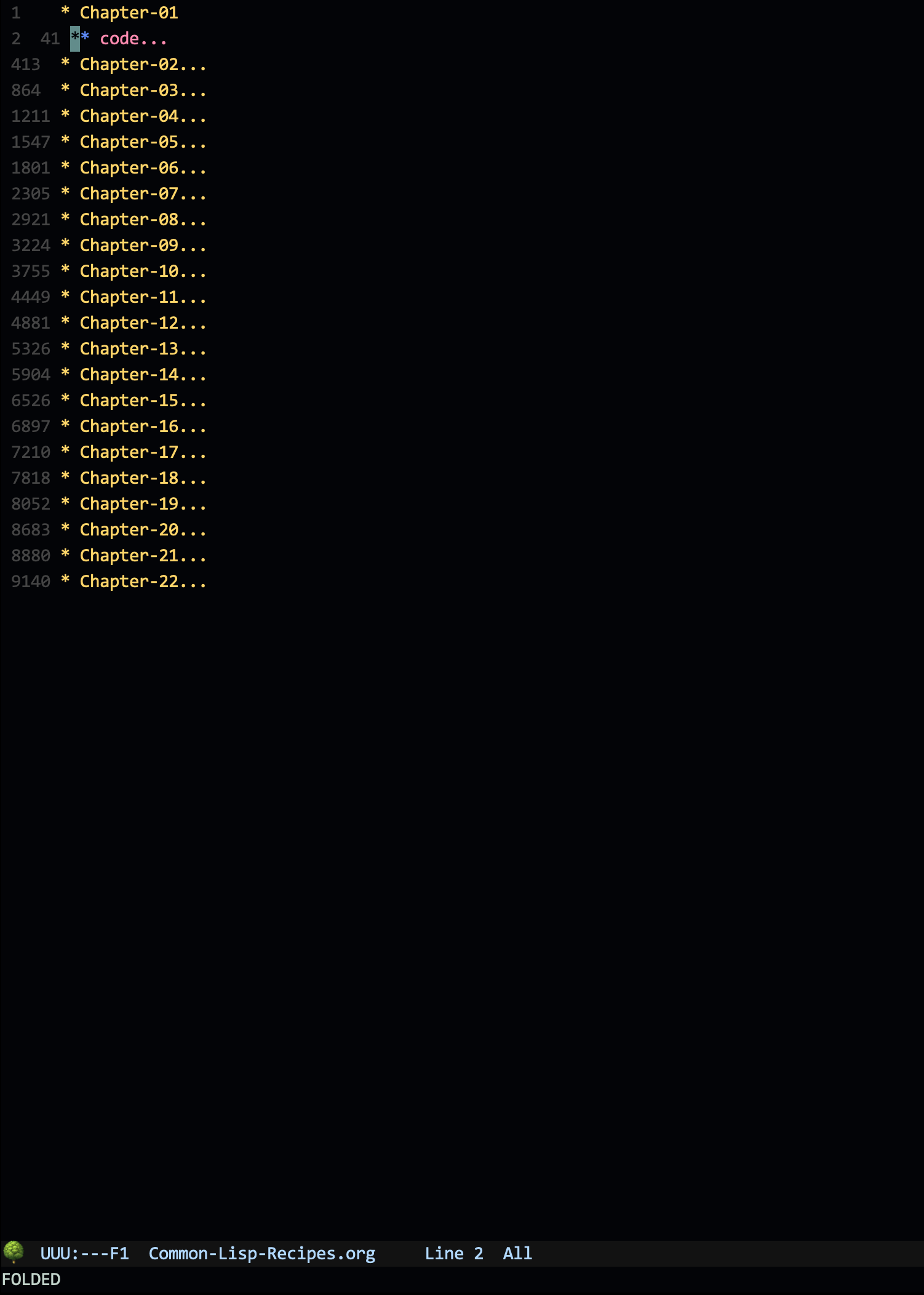
@Soul-Clinic 你这个截图一看让我就感觉是开行号导致的打开慢,我现在把行号显示在header-line的第一个字符和mode-line的第一个字符,不管抬头低头都是一眼看到,就不在需要单独用一列来显示行号了,我win系统打开你的 Common-Lisp-Recipes.org 文件很快,没有卡顿
关了 global-linum-mode 后打开还真是快得多了!
因为我的Emacs默认都是打开 linum-mode 的(大多数文件没有超过一千行)
没想到在Org显示行号的代价那么大(如果没有全部折叠起来可能就不用立刻计算出所有行号~~)
我要 add-hook 来把我默认开启的linum-mode 在 这个文件的Org 里关闭咯~