这个补丁解决了补全菜单项都没有 annotation 时, 补全菜单显示填充空白符的问题。
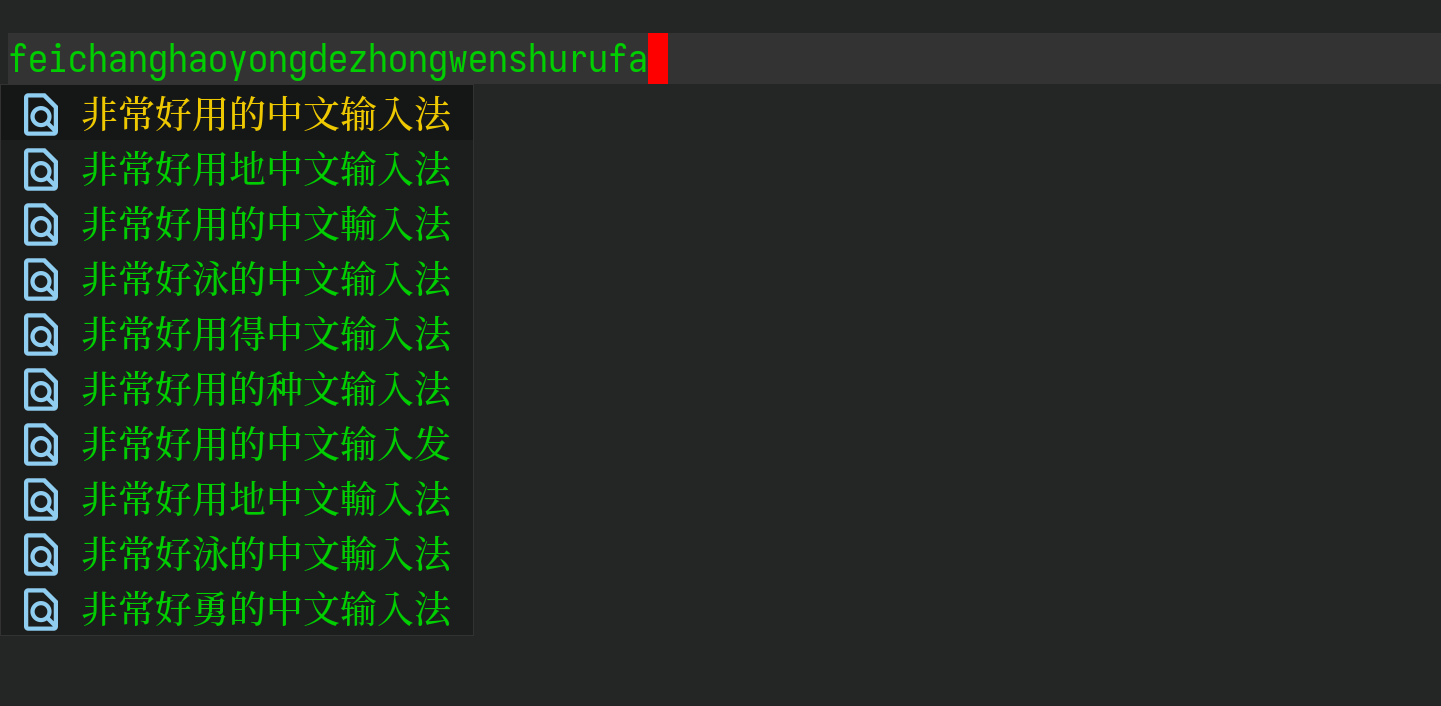
应该可以手动分,需要在 LSP 服务器端先检测到这个符号,然后把分好的结果给输入法,有空时我试试看。
![]()
这个确实,所以如果能用本地数据训练一下可能会好点,这对 emacs 用户很有优势,因为数据大多是纯文本的 org 或 md 格式,但大部分个人机器没法训练。
pip 打包的话,可能等我再加一些额外的接口功能后再考虑,因为现在只是先保证能用,还没有对代码模块化,当前是直接显式地把第三方输入法 import 进来,要发布的话需要能灵活地根据配置来替换后台输入法模块,另外有个问题请教:
如果我想从服务端返回本行的分词信息,比如一句话分了 5 个词,我理解这有点类似 diagnositc 信息,可以传多个 range 回来。但 diagnositic 想留给中文的语法或者错别字检查(如果有现成算法的话),不知道还有哪个 LSP 接口合适?
点赞!
Arch肥猫基于中文wiki构建的词库 Arch Linux - Package Search 我平常用非常不错, 这个词库的客观性很好, 数据足够多, 同时维基词库相对没有个人词库那么容易遇到统计偏差, 也就不会发生词库和用户差异太大后命中率太低的问题。
如果只是告知用户有错误的话, LSP协议都走 Diagnositc 接口, 如果要帮助用户主动修正, 都走 Code Action, lsp-bridge的参考实现连接请参考:
- Elisp命令 lsp-bridge-code-action: lsp-bridge/lsp-bridge.el at 2e01881f0781f7db9701e6c53cba80786a29c535 · manateelazycat/lsp-bridge · GitHub
- LSP消息解析 CodeAction: lsp-bridge/core/handler/code_action.py at 2e01881f0781f7db9701e6c53cba80786a29c535 · manateelazycat/lsp-bridge · GitHub
- Elisp执行 Code Action: lsp-bridge/lsp-bridge.el at 2e01881f0781f7db9701e6c53cba80786a29c535 · manateelazycat/lsp-bridge · GitHub
2 个赞
lspim
lsp-everywhere
一切皆有可能。
1 个赞
当前, 是 rime输入法, 用小狼毫 来自定义一些 业务相关的词库, 且可以 多台机同步这个词库, 后面 可以把这个词库 放到服务器上, 把相关业务 用语 规范好, IT不熟, 还在摸索中, 文学功底不知如何自评, 实用性到可以, 文学功底好 当然好 加分项; AI发展, 估计 只能是 一些普适的场景可以做到, 但就像「考勤」一样, 基本算法 都好理解, 但是 实操中, 还是要 文员 再校对计算, 用人工识别与补入相关 计算参数, 这是不可少的, 「仓库」也同理
1 个赞
很棒的想法,有空很想用ctags来实现这个,自己弄词库,在text mode里面默认补全汉字
谢谢,确实完全可以把这看作一种从 python 端提供补全来源方法,只要有 英文字符串到另一种编码的映射函数(也可以只根据前文内容自动返回补全候选项,都不需要额外的输入触发),然后 acm 提供一个 minibuffer 供选择。
其实楼主的这个想法可以向这篇博客那样, 写拼音输入一些特殊符号, 比如Unicode的点, 特殊括号等.
2 个赞
刚试了一下,只需要定义以下格式字典,然后添加把字典转成候选词的函数
user_define_map = dict([
("8alpha", "α"),
("8beta", "β"),
("8gamma", "γ"),
("8Delta", "Δ")
])
关掉拼音输入法补全,效果如下,这比输入 abbrev 方便,有候选提示
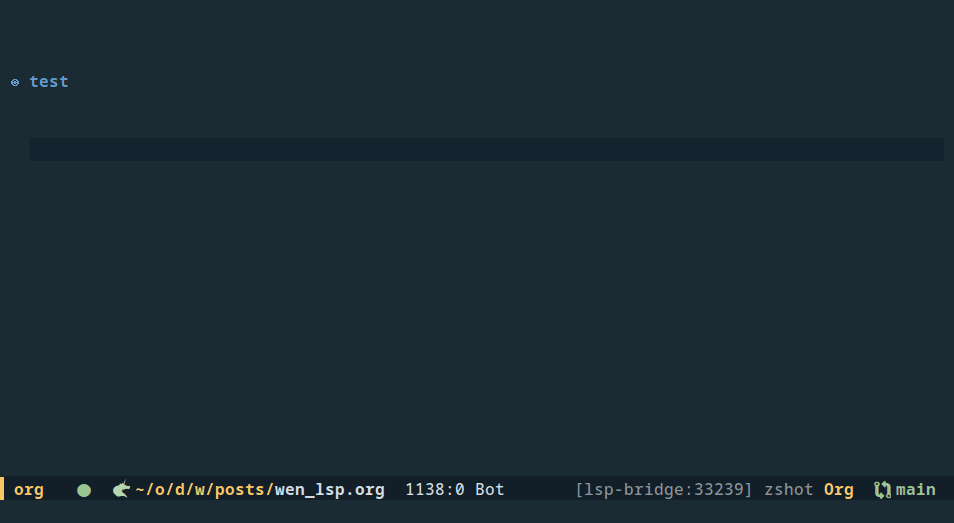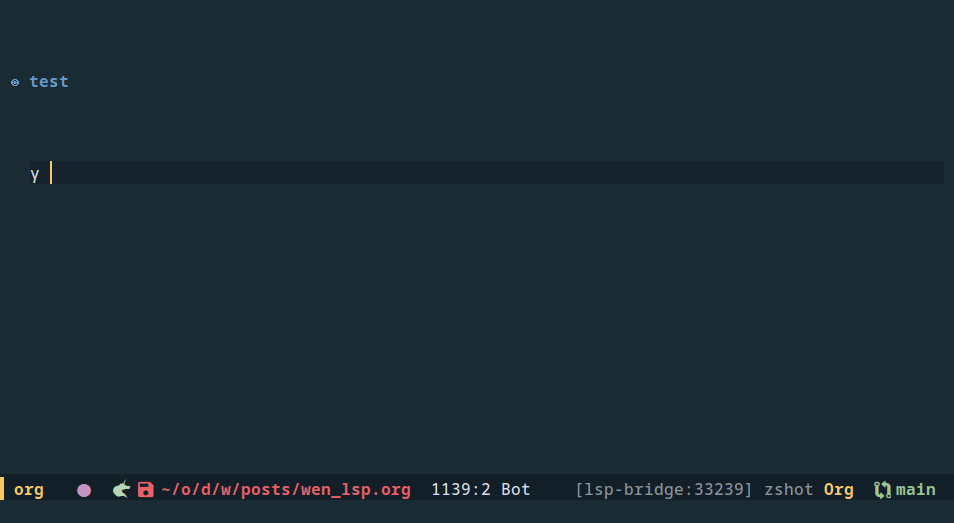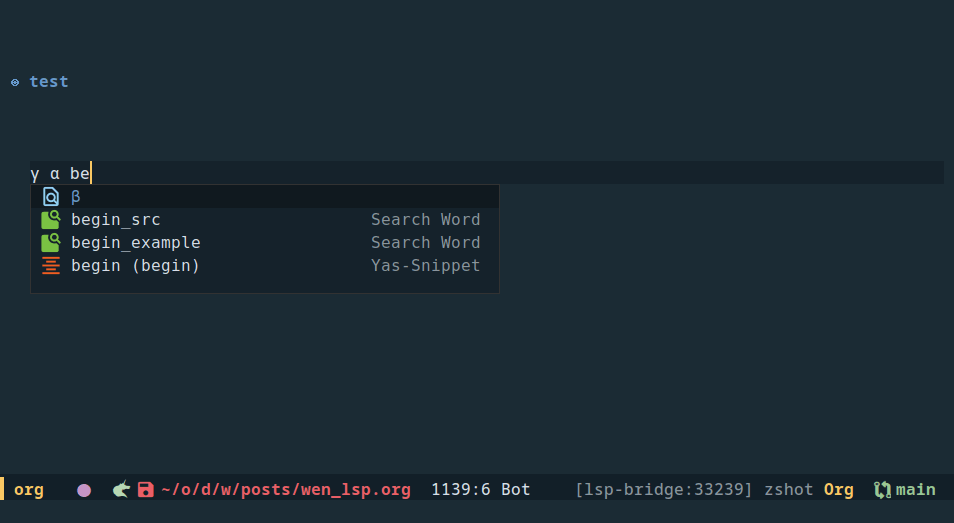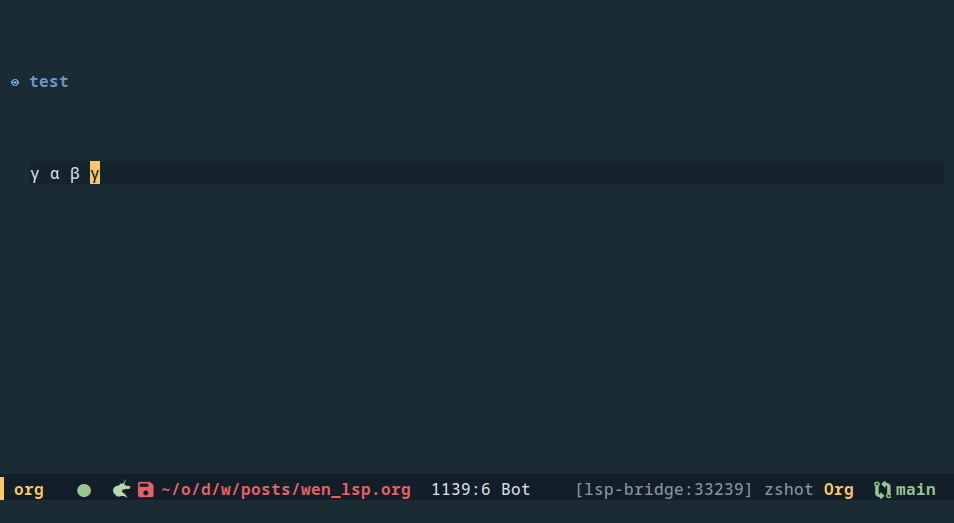
之后把这个字典改成读取用户的 json 或者其他格式的外部文件会更方便些。
1 个赞
感觉这个比 rime 的输入方便啊
rime 实际上输入并不高效
如果是只输入自定义的一些缩写还是很流畅的,这个和 company 加后端是一样的,但我个人觉得在 python 端写会方便些
输入高不高效看的是输入方案和自己的配置吧,rime 只是一个输入法框架。
还有成对的符号,比如 『』,上屏之后再把光标置于其中。
指 rime 引擎自身并不是那么高效,特别是超大词库的情况下,rime 会有卡顿的(不过现在速度越来越快了)
这周新加的试验性功能,都在图里了
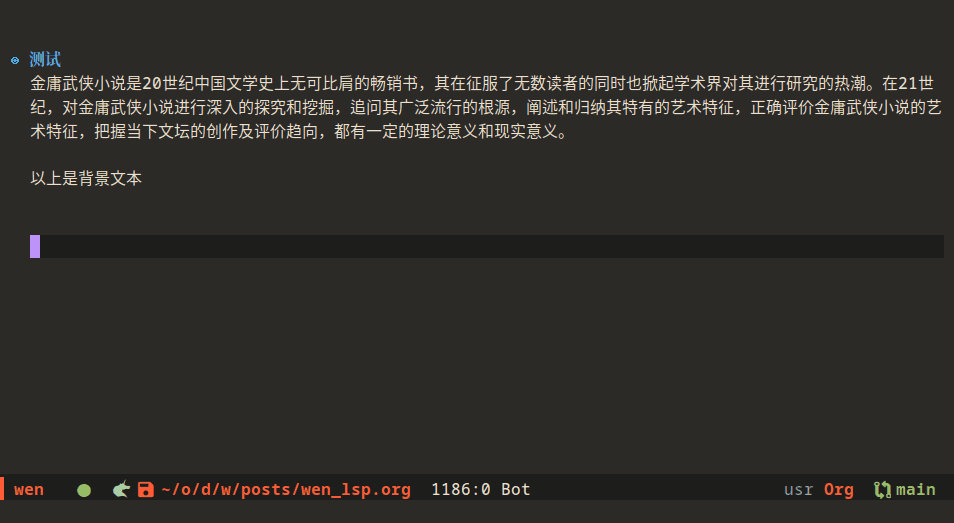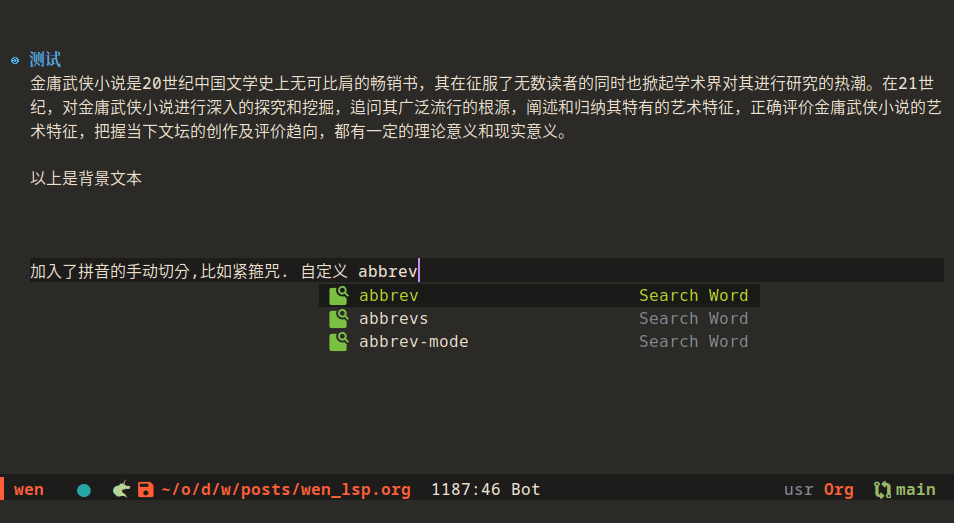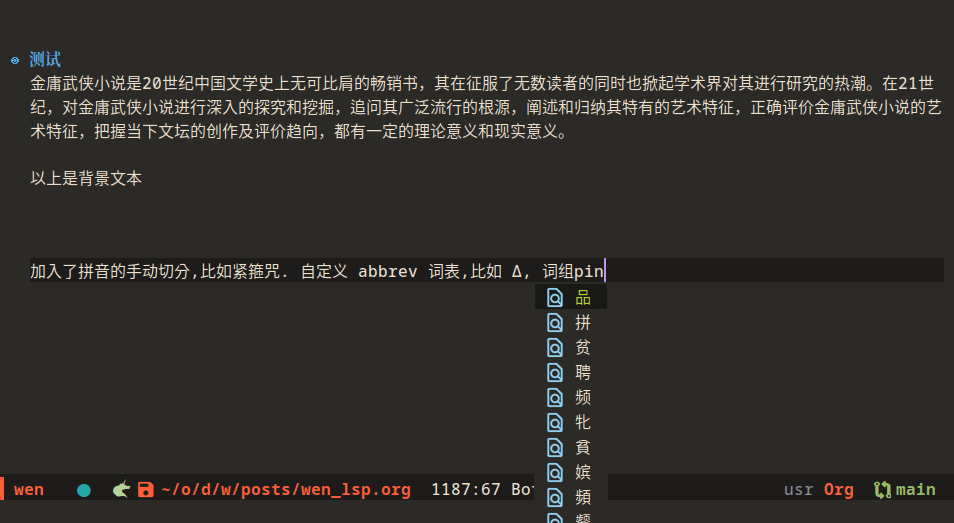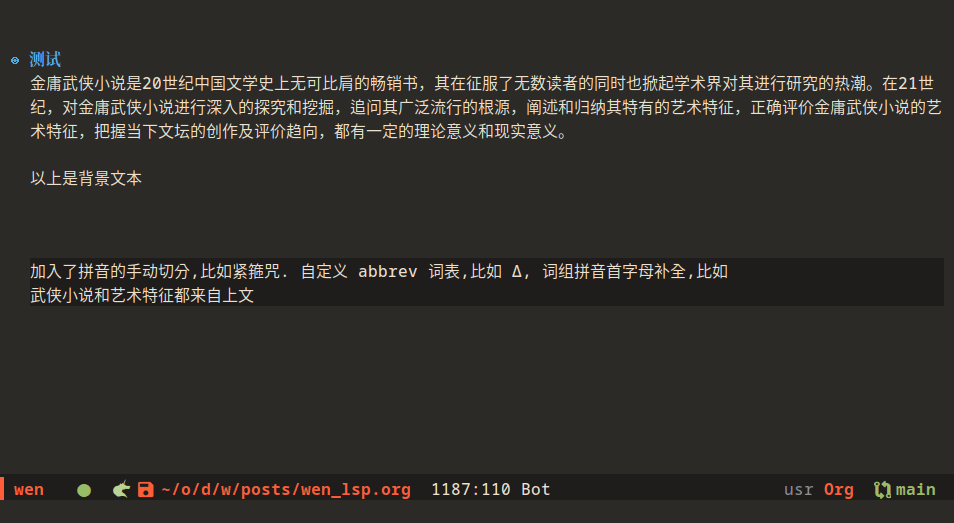
个人感受是:
中文分词补全(包括图中首字母提示补全)这类是典型的“看上去很美“的 idea,按规则来的话,怎么切分都不会有很好的补全效果,也许都得靠 tabnine 一样的大模型连同输入法一起处理(输入拼音或其他编码只是对预测的一个提示)
其实找一个带词频的好的词库就好了,再加上平常用词频学习就好了。
加上自己的词库应该会好点,写这个拼音首字母补全也是想看看怎么用词库来做扩充(当前是从打开的 buffer 里分词获得词库然后转成拼音)。词频学习有个问题要请教,每次用户在 acm 选完词后,得怎么通知 lsp 服务器?好像选择完词是不会有单独的消息的,我现在想到的是在 lsp 服务端写一个 flag 记住上一时刻的 prefix 以及候选词,然后在这一时刻检查光标左侧新增了哪个词,这样基本可以知道用户刚才根据 prefix 从 acm 选了什么词
acm选择词以后基本上是不通知 LSP 服务器的, 因为 LSP 的协议不需要知道用户选择了什么候选词, 这个只能给 acm 定义一个 advice 了, 或者加一个自定义 hook.
我几天体验了一下,传统的拼音输入法因为显示的单词不够多, 除开输入单引号这种手动分词外, 其实每个人都不会输入过多的长句, 因为一旦长句命中不了, 再移动候选词光标的效率就比较低。
LSP Wen Server 多次测试长句的时候, 因为没有传统输入法的停顿(优点),反而有时候会出现句子越长,命中率越短的情况, 不知道不是不是词库的原因, 感觉现在词库只能在4~5个字左右的长度命中率较高, 一旦两个长句放在一起, 补全结果就不知所云了。