刚发现一个有趣的事情,打开项目只浏览代码的话,find def find ref都不起作用,非得输入代码等补全窗口激活,前面俩函数才能正常作用 ![]()
不起作用你是不是直接输快捷键而不是使用M-x,而且你是不是使用evil?如果是这样的话,这个你可能要把lsp-bridge的keymap给evil-make-normlize-keymaps一下。这个是个evil常见的坑。
Support tailwind css. · manateelazycat/lsp-bridge@2475ebd · GitHub tailwindcss 已经支持了。
谢谢大佬,刚刚拉取更新测试了下,org-mode 下补全流畅,逻辑清晰,且有 TabNine 加持,现在用着十分高效,舒服。 ![]()
sdcv 的出现,让我更加喜欢使用 lsp-bridge 的英文帮助功能。
而个人的使用需求是自己制作 stardict for acm-backend-search-sdcv-words-dictionary 字典。在制作词典的过程中也遇到的过一些问题,其中最重要的一个就是:关键字重复时只提示最后一个关键字。
比如,当最终字典中有三个一样的关键字时
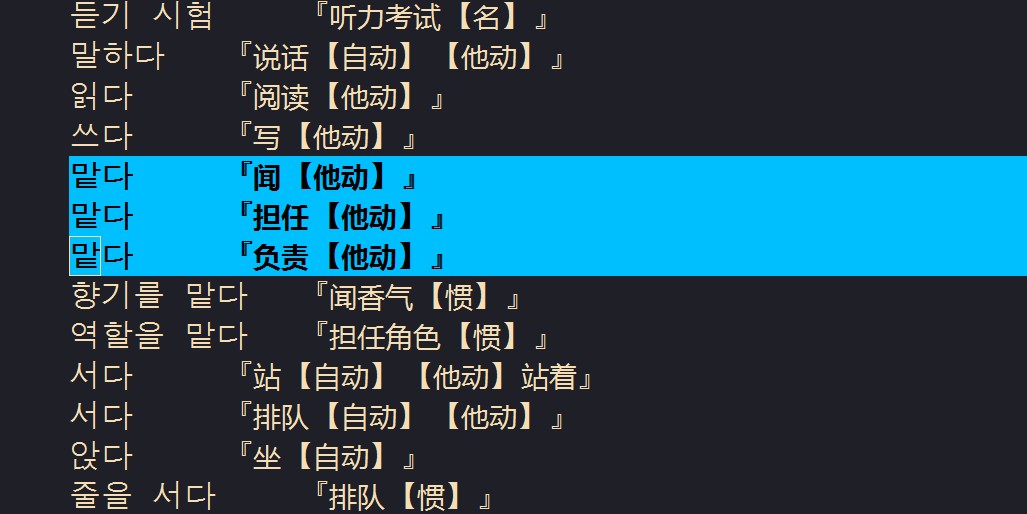
在开启 lsp-bridge-toggle-sdcv-helper 后,只提示第三个(释义为 “负责”的那一个),也就是排在最后的那个。

目前,个人简单粗暴的解决方式是,使用 python 脚本,对制作字典时使用的原始文本文件,编辑修改重复关键字部分,加一个数字编号后缀。
from collections import Counter
# def rename_duplicated_keywords
def rename_dup_keyw(r_f,w_f):
all_key = []
all_value = []
dup_keys =[]
# get the keywords,contents list
with open(r_f,"r",encoding="utf-8") as fr:
for the_str in fr.readlines():
all_key.append(the_str.split("\t")[0])
all_value.append(the_str.split("\t")[1])
# get the duplicated keywords list
b = dict(Counter(all_key))
for k,v in b.items():
if v > 1:
dup_keys.append(k)
# rename the duplicated keywords
for i in dup_keys:
index_list = [a for a, b in enumerate(all_key) if b == i]
for v in range(0,len(index_list)):
all_key[index_list[v]] += str(v + 1)
# save the final contents to a file
with open(w_f,"w",encoding="utf-8") as fr:
for k in all_key:
fr.write(k + '\t' + all_value[all_key.index(k)])
通过此脚本,过滤重复相同的关键字,并修改成带有数字后缀的关键字,实现"去重但保留辨识度"的目的。

再通过这个符合 stardict 词典制作格式的文本文件,使用 stardict-editor 制作成可用的词典。

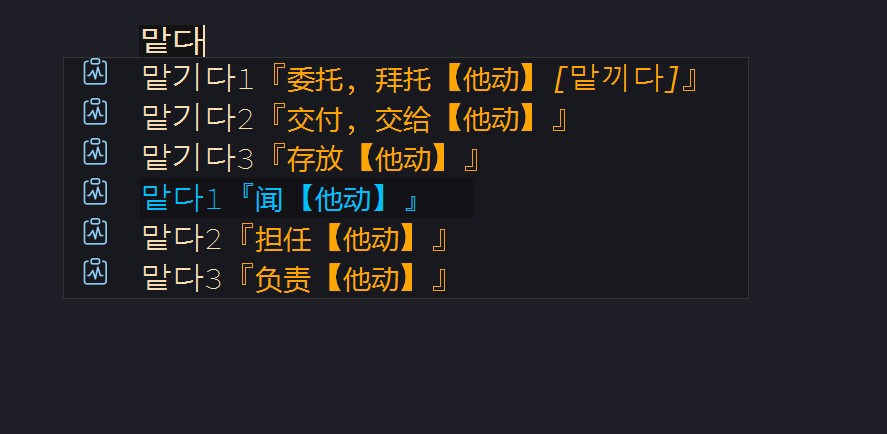
再在 emacs 中开启 lsp-bridge-toggle-sdcv-helper 后,得到了想要的结果,具有不同释义的相同关键字,都可以出现在提示窗口了。
1 个赞
对于 scvt 显示 stardict 的释义不完整的问题,主要现象是:
如果释义内容中带有空格,会将第一个空格之后的内容全部忽略掉不显示。
目前个人简单粗暴的解决方法是在制作字典的源头上,通过找出释义中的空格,然后将它们替换成非空格字符,这样释义部分显示,就等于没有空格了,就变相得显示完整了。
bridge_spc = '\u25ab'
tmp_the_str4 = bridge_spc.join(the_str.split(":")[4].split(" "))
这样,释义部分原本的空格,就显示为指定字符了,也就完整显示出来了

1 个赞
更新到最新版本,在改配置的时候出现以下问题
ERROR:epc:TypeError("object of type 'Symbol' has no len()")
ERROR:epc:Unexpected error
Traceback (most recent call last):
File "C:\Users\donal\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\epc\handler.py", line 242, in _handle
reply = handler(uid, *args)
File "C:\Users\donal\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\epc\utils.py", line 51, in new_method
ret = method(self, *args, **kwds)
File "C:\Users\donal\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\epc\handler.py", line 265, in _handle_call
return ['return', uid, func(*args)]
File "d:\home\vanilla.emacs\site-lisp\lsp-bridge\lsp_bridge.py", line 283, in _do
getattr(getattr(self, obj_name), name)(*args, **kwargs)
File "d:\home\vanilla.emacs\site-lisp\lsp-bridge\core\search_elisp_symbols.py", line 40, in update
self.symbols = sorted(symbols, key=len)
TypeError: object of type 'Symbol' has no len()
更新后,你重启emacs了吗?
这个问题我昨天也碰到了,折腾半天,发现用最小配置没问题 最后定位到下面这个,我这边注释掉就好了。
(when (fboundp 'set-charset-priority)
(set-charset-priority 'Unicode))
2、3年前不知道哪里抄来解决字符集何编码的问题 建议你先用emacs -q ,排查下问题
把unicode相关的配置注释后,这个问题确实没了,但是之前这些配置在的时候也没有出现过这个问题
确实,字数补丁
因为最近把elisp符号搜索挪到python那边去了,所以在idle的时候会更新所有elisp符号。
所以我估计是你们这个配置影响了 all-completions 函数的返回类型。
我这边也碰到了 TypeError: object of type ‘Symbol’ has no len() 这个问题, 我打印了一下信息如下:
type(symbols) : <class 'list'>
type(symbols[0]) : <class 'str'>
symbols[:16] : ['org-super-agenda-date-format', ':top-margin', 'flymake--backend-state-p--cmacro', 'python-imenu-format-parent-item-label', 'prolog-trace-on', 'org-capture-goto-last-stored', 'magit-section-show-headings', 'table--measure-max-width', 'test-rmail-mime-bulk-handler', 'lsp-make-signature-help-options', 'noconfirm', 'lsp-ui-imenu-window-fix-width', 'vc-src-responsible-p', 'log-edit-remember-comment', 'org-element-paragraph-separate', 'idlwave-shell-command-line-to-execute']
这就很奇怪了, 明明是 str 怎么成了symbol了 ![]() 由于个人配置比较多, 简单搜了一下没找到
由于个人配置比较多, 简单搜了一下没找到 set-charset-priority 相关的配置, 就来了个简单粗暴的解决办法
self.symbols = sorted(symbols, key=lambda i: len(str(i)))
强制把 symbol 转成 str 就可以计算len 了
你这个 symbols 才打印了前面 16 个。可能后面有些类型不对。
有道理, 应该就是这样了 ![]()
大佬看看为啥在python项目中 lsp-bridge lsp-bridge-list-workspace-symbols 提示 “LSP server did not return any symbols.”。用的最小配置测试的
pyright 是支持 workspace symbol的
下图是 lsp-ivy lsp-ivy-workspace-symbol 返回的结果。
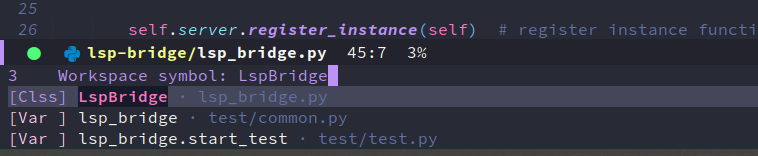
官方文档是这样写的, 但是 pyright 就是啥都不返回。
总怀疑这个标题是不是有些语病……也许应该说是性能最“好”或是速度最“快”?
从搭配的角度来说,您说的对,但是大家都看得懂,当然改过来最好。