又又又重构了…我发誓以后不会这么蛋疼
总之,终于解决了数据一致性的问题了
害我…白忙了好多时间
又又又重构了…我发誓以后不会这么蛋疼
总之,终于解决了数据一致性的问题了
害我…白忙了好多时间
工程重重构很常见,加油!
谢谢zsbd,现在进度稳步加快中,良好的结构就是不一样
终于完善主体部分,今天正式开始实现稍微高级一点的功能,比如查询,还在实现中,还不够完善。

完成通过关键字查询(通用查询,直接查询 标题,标签,还有 属性)。
和导出查询结果(这里的导出并非复制,而是直接移动 org-headline 以及它所包含的所有内容),支持单项导出,多项批量导出,可以导出到一个新文件,也可以导出到指定的文件。
现在还有一个小 bug 要修。
下面是搜索结果页,复选框选中(C-c C-c)就可以执行导出命令,将选中的条目移动到对应的文件里。
这里面已经有几个移动成功的,可以看到几个标识 test3.org 的条目,是移动成功,同时最新的位置也记录在数据库。
今天可以宣布,org-supertag 已经完成了基础工作,明天就可以正式发布了。
目前实现 Tana 大约 60% ~ 70% 的功能,标签的组织和管理方式已经实现了。
就剩下:
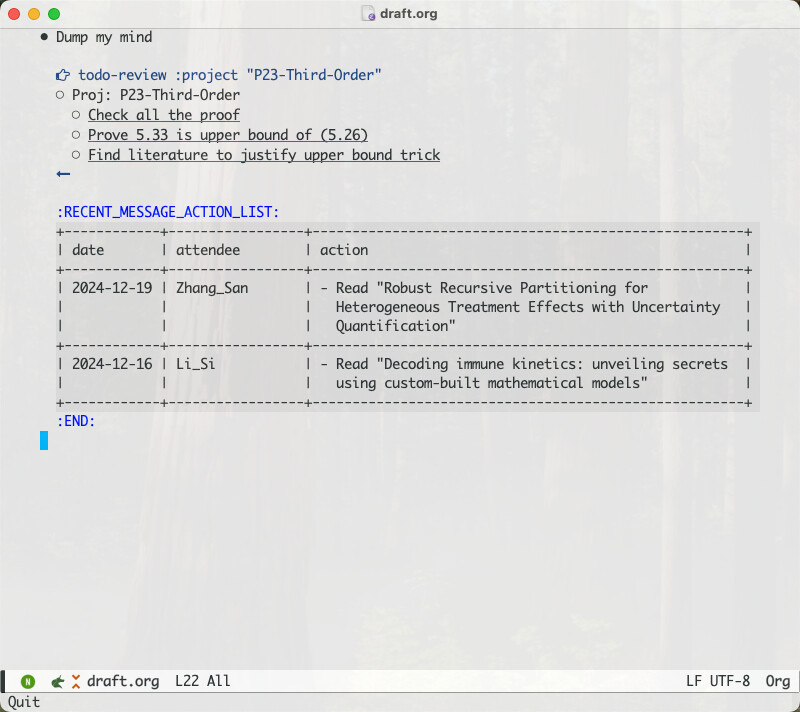
我也复刻了一下 Tana,自用足够。其实org-mode本身就足够强大,我就在 org-set-tags-command 上包了一层用预设的模板设置 property 的指令,其余基本调包就行。用起来感觉最核心的是query,这部分 org-ql 完全可以胜任;AI用gptel,因为可以异步执行不用等。org-ql的参数列表太长,就在外面包一层 dblock 美化一下。下面是效果,第一个列表展示了指定项目的待办事项,第二个用表格罗列了最近一段微信里别人派给我的活:
表格这个是必需用 org-ql 实现的吗?我放弃使用 org-ql 当然是有原因的
不是,org-ql主要是简化了很多搜索和过滤操作,输出格式可以自己写。你觉得org-ql哪里会用起来不太顺?
数据量一大就会变慢。和 org-aganda 一样,因为完全依赖文本系统,所以检索策略是将每一个文件都打开一次,然后完全检索一遍。
不论文件多,还是 org-headline 多,都会不可避免导致性能问题(已经看到诸多吐槽了),以及 org-roam 目前被人诟病的性能问题,也是一样的,因为它的数据层是放在文件本身。
当初设计这个 org-supertag 的根本核心是数据库,而不是 query。 query 是数据库能力的实际运用,或者说是它的实例。
实际上,将文件直接作为数据层的做法,我进行原型验证的 Demo 就是这么设计的,见这里:用 AI 辅助开发的经验二三则(3) :: Space Looming
放弃使用文件系统是最主要的原因,是性能的差距,尽管我没有直接对比,但根据印象,性能相差起码十几倍到上百倍…
文件系统的操作时间是 0.023s 那么数据库的操作时间是 0.00023s
哦哦那确实,主要我supertag还是用在任务管理,所以基本上只会用到一两个存放daily notes的文件。数据量大概是一年左右,所以性能倒还行。
都挺好的,满足自己的需求第一。将检索结果转换成表格的代码可以发出来参考一下吗?