我贴的那个图不能用吗?不能啊,你可以先用 query-replace-regexp 检验一下
我现在要解决的是 chinese-pyim 无痛 中英文切换带来的空格问题.因为我输入英文例如Emacs 之后再输入也会是英文, 然后我要调用 pyim-convert-code-at-point 转成中文,例如Emacs zhongwen,如果没有空格的话,会把Emacs 也转换了, 但是变成中文以后我想删掉那个空格
我发现一个问题,你这一直都是在对string进行操作,你不插入buffer的话是没有用的,为什么不直接对buffer进行操作?
好像是耶.囧,不过我用query-replace-regexp 测试过,还是不行
你确定你都输对了吗?还有你的光标位置是在 buffer 起始处吗?我这边试了是可以的啊
 匹配正则表达式
匹配正则表达式

你试试
M-: (query-replace-regexp "\\(\\cc\\|[[:alnum:]]\\)\\s-+\\(\\cc\\|[[:alnum:]]\\)" "\\1\\2")
以 interactive 方式运行 query-replace-regexp 的时候,正则表达式是不同的
这个1的问题要把我折磨疯了,论坛的 markup 需要改善啊,你 copy 的时候别忘了改过来
起作用了,只是正则表达式匹配不准确
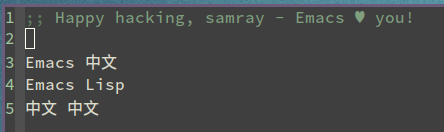
Emacs 中文
Emacs Lisp
中文 中文
都匹配了.
我一直按y,然后就变成了
Emacs中文
EmacsLisp
中文中文
中文字符应该还要区分开来
是的,这就是我刚才说的那个错误的表达式,我刚才直接从kill ring 里调出来,也没看:grin: 第一个是可以用的,匹配两种情况的还需要再改进一下。
嗯嗯,感谢您的耐心解答  我学了正则表达式很久,也练了很多次,感觉还是天书一样,难怪用了一堆正则表达式的 Perl难读
我学了正则表达式很久,也练了很多次,感觉还是天书一样,难怪用了一堆正则表达式的 Perl难读
这个可以用了
"\\(\\cc\\)\\s-+\\([[:alnum:]]\\)\\|\\([[:alnum:]]\\)\\s-+\\(\\cc\\)"
可以匹配两种情况,其它不用变,还是 "\\1\\2"
我没测试,你可以试一下,看行不行。如果可以用的话,请把我的回答标记为答案。
代码块中也 Escape 确实挺烦人的,好像不可能输入 backslash backslash 1 这 3 个字符。需要 Copy 的话,可以点击“编辑本帖”的按钮,然后就可以看到原始的输入了。
多谢 tip,他也可以点我的编辑吗?
Emacs 中文 =>匹配
Emacs Lisp =>不匹配
中文 中文 => 匹配
结果
Emac文
Emacs Lisp
中文中文
应该不行,权限不够。我刚才没有意识到。
这样的话,可以直接访问帖子的原始内容,比如我这一贴:
https://emacs-china.org/raw/2349/37
就是把 elisp 正则表达式如何匹配中文和英文 - #37,来自 xuchunyang 中的 /t/elisp 换成 raw
这样的话就过两遍吧,一遍中英,一遍英中,把我第一次贴的那个正则表达式中英互换一下位置就好了。我刚才翻了一下 pangu-spacing,也是这样处理的,反正也就两次,不像 fontlock 那样过很多遍,应该不会有什么性能问题吧?
这个办法可行,但是能不能令论坛 markup 支持 verbatim,我觉得那样比较符合大多数人的使用习惯,更 user-friendly。
1 个赞
正则表达式 [a-z] \cc 大致可以匹配到,所以用 C-M-% (query-replace-regexp) 的话:
C-M-% \([a-z]\) \(\cc\) RET \1\2 RET y
- Emacs 默认忽略大小写 (
case-fold-search),[a-z]和[a-zA-Z]效果相同 - 从 MiniBuffer 输入不需要 Escape,比如
\cc这三个字符,在C-M-%中只需要输入这三个字符,它们会自动被转换成 String 表示"\\cc" -
\cc或许并不能准确的覆盖中文字符
1 个赞
@xuchunyang 多谢补充
有些情况下我用 [[:multibyte:]] 匹配汉字,比如在 [^[:multibyte:]\n\t ] 里
1 个赞
